- Details
- Published: Thursday, 22 October 2020 06:03
- Hits: 919
Course 1 - week 3 - Shallow Neural Network:
This course introduces 2 layer Neural networks. NN was introduced in previous lecture, but it was mostly logistic regression. In logistic regression, we took a linear function f(x), assigned weights to various pixels, and computed if the picture can be classified as cat or not. It was single layer, as input X passed thru only one function f(x) = σ(w1*x1+w2*x2+...+wn*xn + b).
In Multi layer NN, we pass input X thru 2 functions f(x) and g(x) which may be same or different. If we choose f(x) as a func above, then f(x) returns single value, and passing it thru another function g(x) doesn't give anything new. i.e g(x) and f(x) could be combined as one function h(x). So, in above example, we can combine sigmoid function with g(x) to give a new function h(x)=g(σ(x)). This arrangement implies that instead of choosing sigmoid as an activation function, we chose some other function h(x) as activation function. So, we just replaced one function with another, and 2 layer result could have been achieved with one layer.
What if we allow a combination of f(x) functions to get more curves on the surface that's trying to fit our data set (in case of cat picture, it's fitting our pixels better)? Let's try to make various combinations of f(x) as f1(x), f2(x), etc. Then we can combine these f1(x), f2(x), ... with varying weights and feed that combination to g(x).So, this is what it would look like:
f1(x) = σ(w11*x1+w12*x2+...+w1n*xn + b1)
f2(x) = σ(w21*x1+w22*x2+...+w2n*xn + b2)
..
fk(x) = σ(w21*x1+w22*x2+...+w2n*xn + b2)
Now, we define g(x) the same way as f(x), but now the inputs are the outputs of above functions. Here we assign weights to functions f1(x), f2(x), ... and pass it thru sigmoid func to get g(x)
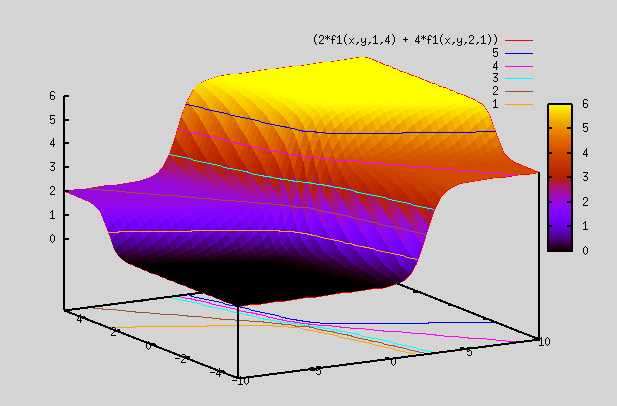
g(x) = σ(v1*f1(x)+v2*f2(x)+...+vn*fk(x) + c)
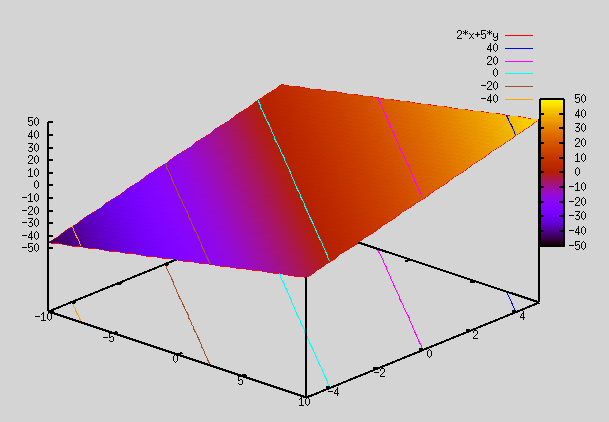
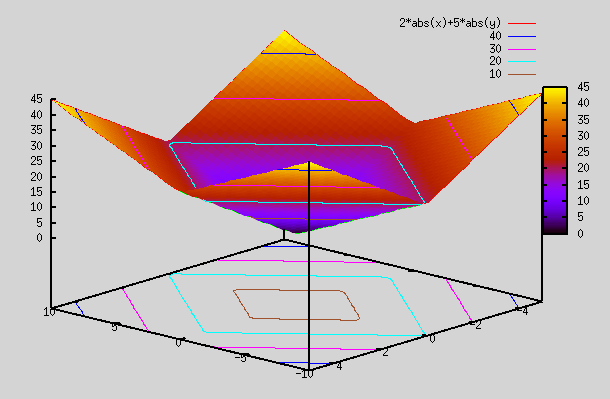
It turns out that this gives a better fit than the logistic regression fit that we attained in week 2 example. Reason is that g(x) in logistic regression was of form g(x) = σ(v1*x1+v2*x2+...+vn*xn + c), but now instead of having x1,x2,... in it's input, it has functions of x1,x2,.. in it's input (i.e f1(x1,x2,...), f2(x1,x2,...),...). This allows it to take more complicated shapes and fit the given data better.
2 Layer NN:
The above scheme becomes a 2 layer NN. It's called a shallow NN, as it has very few layers (in our example, only 2 layers). We can extend this concept from 2 layers to any number of layers, and surprisingly (or may be not so after all), the fit keeps on becoming better. This is because we have more and more dimensions of freedom in playing with variables to get better fit. We may be able to achieve higher accuracy with logistic regression, but it will need infinitely large number of weights to fit the curve. And still, it won't be able to fit the data as it won't be able to generate any curves with a linear function.
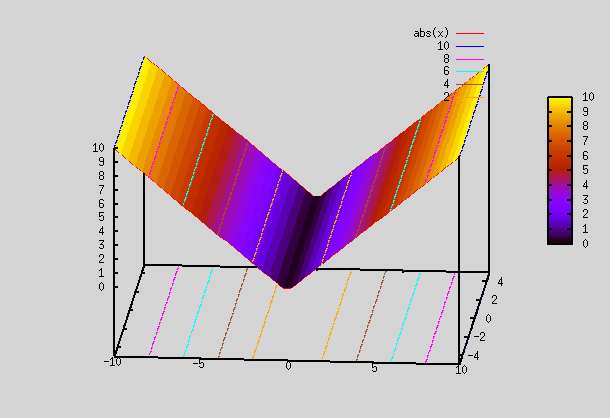
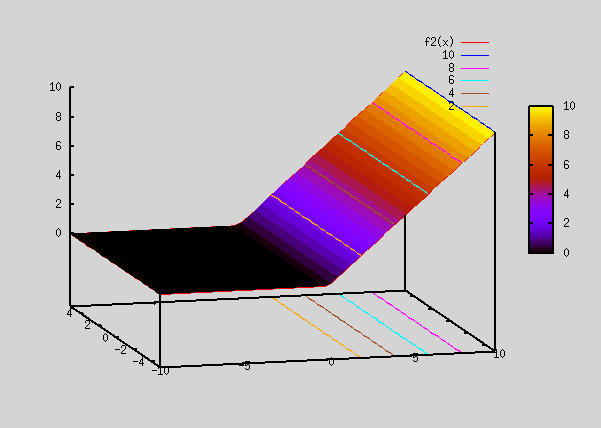
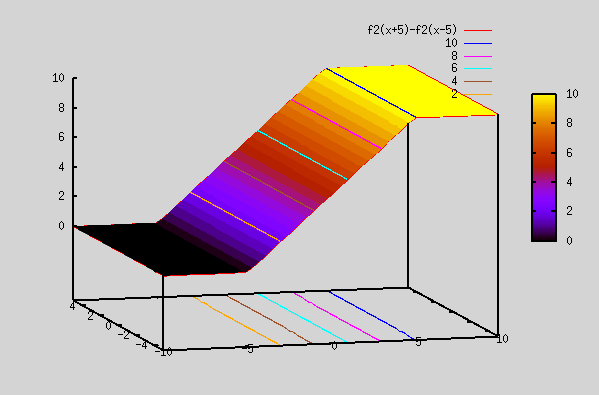
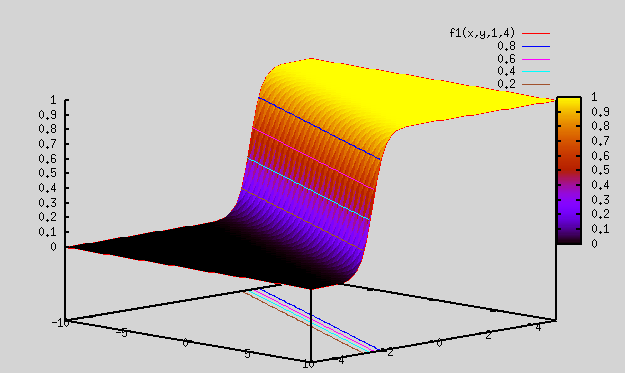
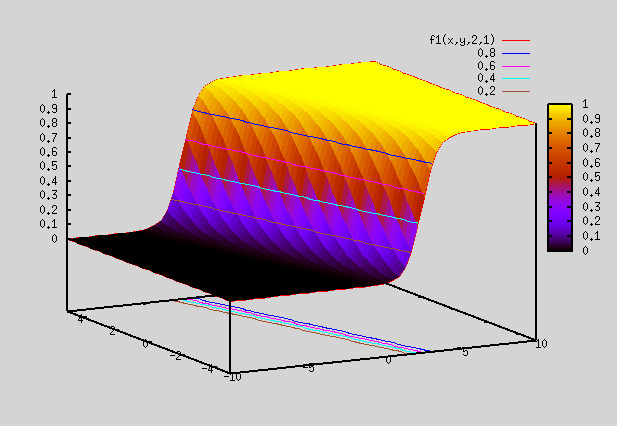
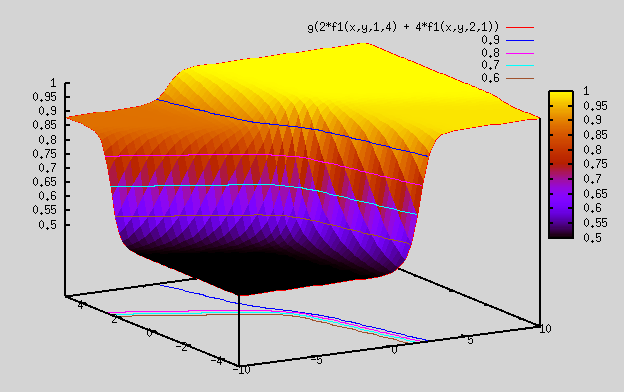
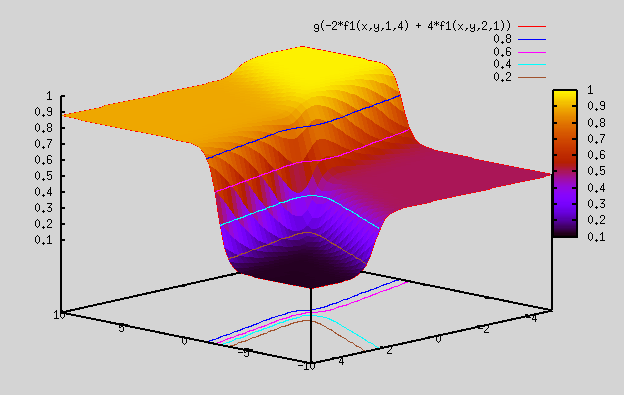
Let's revisit the section on "Best Fit Function". There we saw that sigmoid functions can be linearly added and fed into a sigmoid function to generate complex shapes. We saw plots for 2 dimensional i/p (i.e x,y), but it can be generalized to any number of inputs. By using appr weights and adding sigmoid functions, we were able to generate complex shapes.
ReLU or any other non linear functions can also be used instead of sigmoid functions.
NOTE: One very thing to keep in mind is that weight W need to be initialized to random values, instead of being initialized to 0. The lecture explains why.
Programming Assignment 1: This is a simple 2 layer NN. It tries to predict if a given dot is red or blue given it's location coordinate (x,y). Since the shape is in form of a flower, the 1 layer NN with it's linear equation can never form a boundary that can separate out the blue and red petals (as linear eqn can't form complex surface). Only 2 layer NN and higher layers can form a complex surface that can separate out various regions. We'll run our pgm thru both 1 layer NN and 2 layer NN.
Here's the link to pgm assigment:
Planar_data_classification_with_onehidden_layer_v6c.html
This project has 3 python pgm, that we need to understand.
A. testCases_v2.py => There are bunch of testcases here to test your functions as you write them. In my pgm, I've them turned off.
B. planar_utils.py => this is a pgm that defines couple of functions.
These functions are:
- load_planar_dataset(): This function builds coordinates x1,x2 and corrsesponding color y (red=0, blue=1). The array X=(x1,x2) and Y for all the points is returned back. So, no database is loaded here from any h5 file. It's built within the function.
- load_extra_datasets(): This loads other optional datasets as blobs, circles, etc. These are on same style as petals, where a linera logistic regression can never achieve high enough accuracy.
- plot_decision_boundary(): This plots the 2D contour of the boundary where the function changes value from 0 to 1 or vice versa. However, this boundary is better visualized in 3D. So, I added options for 3D contour, 3D surface and 3D wireframe (on top of default 2D contour). I've set 3D surface as default, as that gives the best visual representation.
- sigmoid(): This calculates sigmoid for a given x (x can be scalar or an array)
We'll import this file in our main pgm.
C. test_cr1_wk3.py => This pgm calls functions in planar_utils. Here, we define our algorithm for 2 layer NN to find optimal weights, by trying out algorithm on training data.. We then apply those weights on training data itself to predict whether the whether the dots were red or blue. There is no separate testing data. We just want to see how well our surface fits training data. Below is the whole pgm:
Below are the functions defined in our pgm:
- layer_sizes() => Given X,Y as i/p array, it returns size of input layer, hidden layer and output layer
- initialize_parameters() => initializes W1,b1 and W2,b2 arrays. W1, W2 are init with random values (Very important to have random values instead of 0), while b1,b2 are init to 0. It puts these 4 arrays in dictionary "parameters" and returns that. NOTE: To be succinct, we will use w,b to mean W1,b1,W2,b2, going forward.
- forward_propagation() => It computes output Y hat (i.e output A2). Given X, parameters (parameters has all w,b), this func calculates Z1, A1, Z2, A2 which are stored in dictionary "cache" and returned. NOTE: here didn't use sigmoid func for both layers. Instead we used tanh function for 1st layer (hidden layer), and sigmoid for next layer (output layer). Lectures explain it why.
- compute_cost() => computes cost (which is the log function of A2,Y).
- backward_propagation() => This computes gradients dw1, db1, dw2, db2 by using the formulas in lecture. It stores dw1, db1, dw2, db2 in dictionary "grads". It returns dictionary "grads". NOTE: above 3 functions were combined into one as propagate() in the previous exercise from week2, but here they are separated out for clarity.
- update_parameters() => This function computes new w,b given old w,b and dw,db. It doesn't iterate here, rather iteration is done in nn_model() below
- nn_model() => This is the main func that will be called in our pgm. We provide the training data array (both X,Y) as i/p to this func. It then returns to us the optimal parameters (w,b). It calls above functions as shown below:
- calls func initialize_parameters() to init w,b,
- It then iterates thru cost function to find optimal values of w,b that gives the lowest cost. It forms a "for" loop for predetermined number of iterations. Within each loop, it calls these functions:
- forward_propagation() => Given values of X,w,b, it computes A2(i.e Y hat). It returns A2 and cache.
- compute_cost() => Given A2,Y, parameters (w,b), it computes cost
- backward_propagation => Given X,Y, parameters (w,b) and cache (which stores intermediate Z and A), it computes dw,db and stores it in grads.
- update_parameters() => This computes new values of w,b using old w,b and gradients dw,db. New "parameters" dictionary is returned.
- In beginning, w and b are initialized. We start the loop and in first iteration, we run the 4 functions listed above to get new w,b based on dw, db, and learning rate chosen. Then we start with next iteration. In next iteration, we repeat the process with newly computed values of w,b fed into the 4 functions to get even newer dw, db, and update w,b. We keep on repeating this process for "num_iterations", until we get optimal w,b which hopefully give lot lower cost than what we started with.
- It then returns dictionary "parameters" containing optimal W1,b1,W2,b2
- predict() => Given input picture array X and weight w,b, it predicts Y (i.e whether point is blue or not). It uses w,b calculated using nn_model() function. It calls forward_propagation() func to get A2 (i.e Y hat). If A2>0.5, it sets predictions to "1" else sets it to 0, and returns array "predictions".
- Accuracy is then reported for all coordinates on what color they actually were vs what our pgm predicted.
Below is the explanation of main code (after we have defined our functions as above):
- We get our datset X,Y from any of the multiple sets available. We have our petal flower set (which is the default set). We can also choose optional noisy_circles, noisy_moons, blobs, gaussian_quantiles. We use func loadplanar_dataset() to load petal dataset, while we use load_extra_datasets() to load the other 4 datasets. We plot the data X,Y in a scatter plot.
- We then run 2 classifiers on our data: 1 is logistic regression, while other is 2 layer NN:
- Logistic regression:
- Here we run logistic regression classifier on this X,Y dataset. Instead of building our own logistic regression classifier (as we did in week 2 exercise), we use sklearn's inbuilt classifier on X,Y set.
- We then use func plot_decision_boundary() to plot 2D/3D decision boundary (or predicted Y values, i.e Y hat values) to check how how fitting surface looks like with logistic regression classifier. It's a a single sigmoid function as expected (with a straight line seen in 2D contour)
- Then we print accuracy of logistic regression which is pretty low as expected.
- Two layer NN:
- Here we run our 2 layer NN. We call function nn_model() with i/p X,Y and number of hidden layers set to 4.
- Next, we use func plot_decision_boundary() to plot 2D/3D decision boundary (the same way as in regression classifier)
- Then we print accuracy of NN which is lot higher than logistic regression.
- Logistic regression:
- In above exercise, we used a fixed number "4" for our hidden layer number. We would like to explore what does increasing the number of hidden layers do on the accuracy of prediction. So, we repeat the same exercise as we did in 2 layer NN, but now we vary hidden layer size from 1 to 50. As expected, larger the number of hidden layers, more the number of surfaces we have to play with, and hence better the fit we can achieve. So, prediction accuracy goes to 90%.
Below are the plots for different hidden layer size (sizes ranging from 1 to 20). NOTE: number of layers is still 2.
1. Petal data: First we show plots for Petal data set
A. below is how petal data looks like. Here o/p Y is the color, while i/p X are the coordinates (x1,x2)

B. When we run logistic regression on above data to get best fit, this is how logistic regression final output Y plot looks like:

C. Now, we run the same datset on optimal w,b calculated in our pgm above, but with different size of hidden layer ranging from 1 to 20. Here we plot A2 (not Y, but Y hat), so that we can see what values these sigmoid plots range from (i.e did they all the way to 0 or 1, or were they stuck in between values). If we plot finally Y (predicted values), then we lose this info. As can be seen, we get more and more tanh plots to arrange and get better fit, as we increase hidden layer size. Hidden layer size of 1 means only 1 tanh function, size=2 means 2 tanh functions, size=3 means 3 tanh functions, and so on. So, for size=3, activation function A2=C1*tanh+C2*tanh+C3*tanh can generate a lot more surfaces (about 3+3+1=7 possible surfaces).






2. noisy circles data: Next we show data for Noisy circles data set
A. below is how noisy circles data looks like. Here o/p Y is the color, while i/p X are the coordinates (x1,x2).

B. When we run logistic regression on above data to get best fit, this is how logistic regression final output Y plot looks like:

C. Now, we run the same datset on optimal w,b calculated in our pgm above, but with different size of hidden layer ranging from 1 to 20. As in petals case, we plot A2 (not Y, but Y hat). Results show the same thing as petals case: we get better fit, as we increase hidden layer size. Here blue and red dots are more randomly spread, so there should be more of tanh functions that are added together, so that they can separate out red and blue dots. So, a larger hidden layer size helps.






Summary:
By finishing this exercise, we learnt how to build 2 Layer NN and figure out optimal weight for coordiantes (x,y) so that it can predict blue vs red dot. We played around with different size of hidden layer, and saw that higher the size of hidden layer, better is the fit, though beyond a certain optimal number, increasing the size of hidden layers don't add any extra value. We compared results to those predicted by logistic regression. Logistic regression (which is basically a single layer NN) could never match the accuracy provided by NN with 2 layer.